Continuous Delivery with ATDD and Feature Flags
- January 26, 2024 |
- 5 min read
Acceptance Test-Driven Development
Practicing TDD increases flow and improves design as long as we test the behavior of each component instead of its implementation details. Unit testing with TDD focuses on the lower component level, but we can also apply the practice at a higher level by first writing an acceptance test for each user scenario (i.e. acceptance criteria) like this:
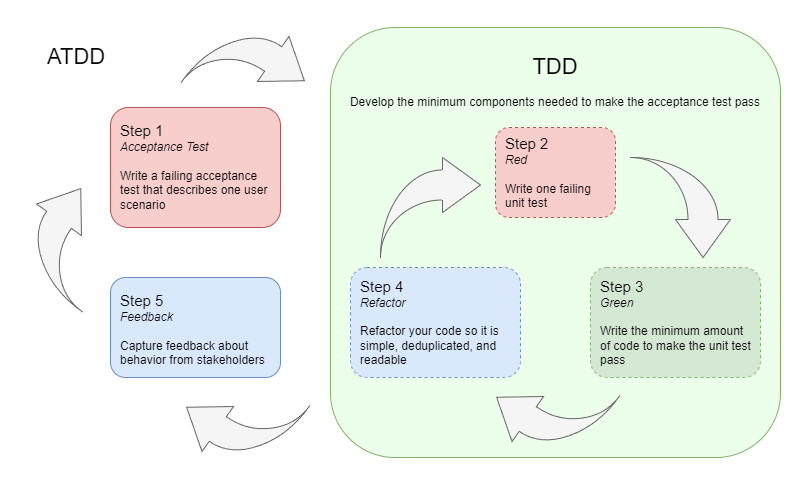 Acceptance Test-Driven Development (ATDD) is also known as Specification by Example, Double-Loop TDD, Story Test Driven Development, or Behavior Driven Development, though some would argue there are differences between these terms.
Acceptance Test-Driven Development (ATDD) is also known as Specification by Example, Double-Loop TDD, Story Test Driven Development, or Behavior Driven Development, though some would argue there are differences between these terms.
The CI Problem
Part 1
How do we frequently integrate small, incremental changes within the inner TDD loop? Each change is only a tiny slice of behavior, so the scenario will fail until all slices are complete. The deployability of our software should depend on the success of our acceptance tests, so our pipeline will fail until the scenario is completely functional.
In the past I've done things like comment out the acceptance test I'm currently working on. But that is error-prone, looks messy in version control, and makes it more difficult for others on the team to run the tests. I've also waited until the entire scenario is complete before pushing my changes. But that is not integrating fast enough: I want to be able to safely merge my code after every short TDD cycle.
Part 2
If we solve this particular issue, then it causes another one: merging rough and unfinished features into trunk increases the cost of accidentally enabling the feature flag and breaking production.
Proposal
We can solve this by setting up our CI/CD pipeline to integrate aspects of feature flagging with acceptance testing. Ideally we are able to fully control everything within our test specifications in version control without switching to an external system and breaking our focus.
When writing acceptance tests, we tag the unfinished tests as "pending" and our pipeline only gates deployment by running completed tests. We can still run the pending tests locally during development. After a scenario is complete, we remove the "pending" tag and the pipeline now runs that test. Most test frameworks provide tagging functionality.
But now that we're deploying code during development that is not gated behind an acceptance test, we're introducing more risk to production. We can leverage an integration with our feature flagging system to reduce this risk by setting up pipeline rules to:
- protect features from being enabled in production before they are ready
- protect unfinished code from being deployed behind an enabled feature flag
Additionally, we could automatically register feature flags when a feature is complete to reduce some toil.
New Feature Workflow
Here's a walkthrough of the workflow when building a new feature.
Developer Experience
- Break a feature into user scenarios (i.e. acceptance criteria) with product stakeholders
- Stub out each scenario as an acceptance test, tagged with the feature flag name and "pending"
- Write a single acceptance test
- Use the TDD cycle to deliver incremental changes behind the feature flag and make the acceptance test pass
- Remove the "pending" tag from the completed acceptance test
- Demo and capture feedback about the new behavior from stakeholders
- If the feature is not yet complete, go back to Step 3
Notice that at any step in this process, you can safely merge into trunk without breaking the pipeline. Here's the relevant logic in the pipeline that happens automatically:
Pipeline Logic
- Parse acceptance test tags
- If the feature flag doesn't exist in the feature flag system, create it
- If the test is "pending"
- And its associated feature flag is enabled for any production users, fail the pipeline
- Otherwise, disable or hide the flag in the feature flag system, so it cannot be enabled for production users
- Run acceptance tests except those that are pending
Changing Existing Features
When changing the scenarios for an existing feature, we also now have some protection against breaking a feature that has already been released. If we need to change the behavior of a released feature, we are enforcing that it is implemented under a new feature flag, so we don't break the user experience during development.
Reducing Toil
Integrating your feature flag solution with your pipeline in this manner also opens up some additional automation opportunities. For instance, you could remove feature flags from the system when a developer removes them from the scenario tags, but only if the feature has been released for at least 2 weeks and there are no instances of it in the code. Or you could log a warning if a feature has been released for over 4 weeks without being removed from the code yet.
Further Reading
- Coding Is Like Cooking » Blog Archive » Outside-In development with Double Loop TDD
- Acceptance Testing: What Are Acceptance Test and why They Matter
- Acceptance testing your Go CLI. I’m a fan of Acceptance Test Driven… | by William Martin | Medium
- Double-Loop TDD
- Acceptance Test Driven Development (ATDD) | Agile Alliance
- What Is Acceptance Test Driven Development (ATDD)
- How to Write Automation Tests for Feature Flags with Cypress.io and Selenium | by Todd Seller | Engineers @ Optimizely | Medium